- 목차
들어가는 말
1. 데이터프레임 열 데이터 삭제
2. 데이터프레임 행 데이터 삭제
갈무리
![[그림 1] 데이터프레임 행, 열 삭제](https://blog.kakaocdn.net/dn/bgsiKM/btr5Qha8fkH/W1eKBJzvtR0K9tHk7Sn0TK/img.jpg)
들어가는 말
pandas Dataframe을 사용하면서 분석이나 기타 활용 목적으로 특정 행이나 열 데이터를 삭제해야 하는 순간이 있습니다.
기본적으로 Dataframe은 .drop() 메서드를 이용해서 행과 열 데이터를 삭제합니다. 특정 범위나 조건을 걸고 삭제를 하고 싶다면 .drop() 메서드에 조건 서식의 인덱스를 입력하거나 .iloc[]를 사용합니다. 각 메서드의 기본 형태를 살펴보고 활용 예시를 알아보겠습니다.
import pandas as pd
name = ['홍길동', '김철수', '나일류']
ID = ['apple', 'banaba', 'coconut']
mail = ['apple@gaegosaeng.com', 'banana@gaegosaeng.com', 'coconut@gaegosaeng.com']
name2 = ['홍길동', '김철수', '나일류','박민수','변지성','민지선', '강민지', '고목나','홍길동']
ID2 = ['apple', 'banaba', 'coconut','durian','egg','jazz', 'kiwi', 'lemon','honey']
mail2 = ['apple@gaegosaeng.com', 'banana@gaegosaeng.com', 'coconut@gaegosaeng.com',
'durian@gaegosaeng.com','egg@gaegosaeng.com','jazz@gaegosaeng.com',
'kiwi@gaegosaeng.com', 'lemon@gaegosaeng.com','honey@gaegosaeng.com']
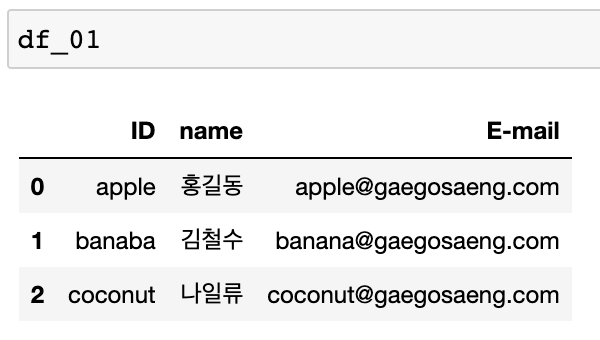
df_01 = pd.DataFrame({'ID': ID, 'name': name, 'E-mail': mail})
df_02 = pd.DataFrame({'ID': ID2, 'name': name2, 'E-mail': mail2})[코드 1] 행, 열 데이터 삭제 연습을 위한 기본 데이터프레임

1) .drop() 메서드
#drop() 메서드의 기본 구조
변경된 데이터프레임 = 원본 데이터프레임.drop([삭제하고픈 행 번호] 또는 columns='삭제하고자 하는 열 이름', axis=행/열 선택)
#원본 데이터프레임의 데이터를 삭제할 때 - inplace=True
원본 데이터프레임.drop([삭제하고픈 행 번호] 또는 columns='삭제하고자 하는 열 이름', axis=행/열 선택, inplace=Bool타입)[코드 2] .drop() 메서드의 기본 구조
drop() 메서드 안에서 행을 삭제하고 싶다면 [행 번호]를, 열을 삭제하고 싶다면 columns='열 이름'을 인자로 받습니다. axis=인자는 0일 때는 '행'을 의미하며, 1일 때는 '열'을 뜻합니다. 원본 데이터프레임에서 데이터 값을 삭제하고 싶다면 메서드 안에 inplace=True 인자를 넣어서 원본 데이터 값을 수정할 수 있습니다. 특정 범위의 인덱스를 기준으로 행 데이터를 삭제하건, 조건 인자를 넣어 행 데이터를 삭제할 수 있습니다. 그 방식은 '행 데이터 삭제' 단락에서 자세히 다루겠습니다.
2) .iloc[] 의 기본 구조
변경된 데이터프레임 = 원본 데이터프레임.iloc[:n][코드 3] .iloc[] 의 기본 구조
.iloc[:n]에서 n은 임의의 index 번호 입니다. 만약 4를 포함한 다음 index 모두를 삭제하고 싶다면 n에 4를 대입해서 입력하면 처리됩니다. 해당 부분도 '행 데이터 삭제' 단락에서 자세히 다루겠습니다.
1. 데이터프레임 열 데이터 삭제
#열 삭제
df_03=df_01.drop(columns='E-mail', axis=1)[코드 4] 데이터프레임에서 열 데이터 삭제
.drop() 메서드 안에 columns=인자에 삭제를 원하는 열 이름을 입력하고 axis=1로 열을 삭제하려고 한다고 선언합니다. 수정된 데이터프레임은 df_03이라는 새로운 데이터프레임에 할당합니다.
![[그림 3] 데이터프레임 열 삭제](https://blog.kakaocdn.net/dn/c37Wzy/btr5qt3KlQS/cQ2So7O1foX2a6ArFd7Tv1/img.png)
그 결과 df_03은 'E-mail'열이 삭제된 수정된 데이터프레임이 되었습니다. 당연한 얘기지만 원본 데이터프레임 df_01은 수정되지 않은 그대로입니다. [그림 4] 처럼 df_01 데이터프레임을 다시 호출해 보면 원본 그대로를 유지하고 있음을 알 수 있습니다.
![[그림 4] 바뀌지 않은 원본 데이터프레임](https://blog.kakaocdn.net/dn/bAQ0Hd/btr5qdNmzVV/I4NSonqQcDAQhVoGu5kmAk/img.png)
#원본 데이터프레임에서 열 삭제_inplace=True
df_01.drop(columns='E-mail', axis=1, inplace=True)[코드 5] 원본 데이터프레임에서 열 데이터 삭제
원본 데이터프레임을 수정하고 싶다면 inplace=인자를 추가해야 합니다. 이 인자는 Bool타입을 값으로 받습니다. True는 inplace를 활성화하고, False는 비활성화 합니다. inplace를 명시하지 않는다면 기본적으로 .drop()메서드는 inplace=False를 디폴트 값으로 갖습니다. 참고로 inplace는 영어로 'in plcae = 제자리에 (있는)...'라는 뜻을 의미합니다. 그렇게 때문에 원본 데이터프레임이 수정되는 것입니다.
![[그림 5] 원본 데이터프레임 열 삭제](https://blog.kakaocdn.net/dn/FMpD0/btr5jb4HU2w/Wia6AxCyts9e65rPjJhM71/img.png)
2. 데이터프레임 행 데이터 삭제
1) 인덱스를 이용한 행 삭제
# 1)인덱스를 이용한 행 삭제
df_04 = df_02.drop([8],axis=0)[코드 6] 인덱스를 이용한 행 삭제
인덱스로 특정 행을 삭제할 때는 .drop() 메서드에 [인덱스 값]을 입력하고, axis=0으로 행에 대해서 작업한다고 선언합니다. 그 결과 [그림 6]처럼 index값 8행이 삭제된 것을 알 수 있습니다.
![[그림 6] 인덱스를 이용한 행 삭제](https://blog.kakaocdn.net/dn/MTZTc/btr5pb3FmSs/vsRTnI6dOAUt3ibKolJgD0/img.png)
2) 인덱스 범위를 이용한 복수의 행 삭제
# 2) 인덱스 범위를 이용해 행 삭제
# 2에서 4까지 범위 생성. 시작지점은 포함, 끝나는 지점은 비포함. 따라서 2, 3 인덱스만 삭제됨
df_04 = df_02.drop(df_02.index[2:4])[코드 7] 인덱스 범위를 이용한 복수의 행 삭제
인덱스 범위로 여러 개의 행을 삭제할 때는 .drop() 메서드 안에 '원본 데이터프레임.index[i:j]'를 선언하므로써 구현합니다. i는 index 시작점입니다. j는 끝나는 index 지점입니다. 주의할 점은 끝나는 지점은 삭제하는 행 범위에서 제외한다는 것입니다. 부등호로 표시하면 다음과 같습니다.
i ≤ 삭제 하는 행 범위 < j
[코드 7]은 df_02 데이터프레임에서 index 2부터 index 3까지의 행을 삭제합니다. 그 결과 [그림 7]처럼 index 2, index 3 행이 삭제된 것을 확인할 수 있습니다.
![[그림 7] 인덱스 범위를 이용한 복수의 행 삭제](https://blog.kakaocdn.net/dn/cbtIOP/btr5oAQbyuH/DILza6ZKKoKkI55HocHJz1/img.png)
3) 인덱스 시작지점부터 아래에 속한 모든 행 삭제
#인덱스 시작지점부터 아래에 속한 모든 행 삭제
#:n n을 포함한 n이후의 인덱스를 모두 삭제, 여기서는 표기 인덱스가 아닌 실제 인덱스를 따릅니다.
df_04 = df_02.iloc[:4][코드 8] 인덱스 시작지점부터 아래에 속한 모든 행 삭제
.iloc[:n]는 n에 입력한 index 부터 아래에 있는 모든 행을 삭제합니다. [코드 8]에서 n에 4를 입력해서 index 4를 포함한 아래 행 모두를 삭제합니다. [그림 8]을 보면 그 결과를 확인할 수 있습니다.
![[그림 8] 특정 인덱스 시작점부터 아래의 모든 행 삭제](https://blog.kakaocdn.net/dn/djXgUP/btr5oACAF8s/OYxDQUm8pG12CGOozg4sk1/img.png)
그렇다면 이런 질문은 어떨까요? index 가 4인 행이 불규친하게 있을 때입니다. 그럴 땐 그 index 행부터 아래가 삭제 될까요? 아니면 위에서부터 다섯 번째 행(실질적 index 4)부터 아래가 삭제될까요?
#별도의 인덱스를 가지는 df_05
df_05 = pd.DataFrame({'ID': ID2, 'name': name2, 'E-mail': mail2},
index= [2,3,1,0,5,4,6,7,8])[코드 9] 별도의 인덱스를 가지는 df_05
![[그림 9] 별도의 인덱스를 가지는 데이터프레임 df_05](https://blog.kakaocdn.net/dn/dadn92/btr5rgwo4eL/QY6lFmpkwdJRGoInoFHiU0/img.png)
df_05는 index 값으로 불규칙한 숫자를 갖는 데이터프레임입니다. 여기서 표기된 index 4의 행은 두 번째 행입니다. 이제 여기서 [코드 10]처럼 index 4에서 아래 행을 삭제하도록 해봅시다.
#:n n을 포함한 n이후의 인덱스를 모두 삭제, 여기서는 표기 인덱스가 아닌 실제 인덱스를 따릅니다.
df_06= df_05.iloc[:4][코드 10] 별도의 인덱스를 따르는 데이터프레임에서 n값의 의미
![[그림 10] 별도의 인덱스를 따르는 데이터프레임에서 n값의 의미](https://blog.kakaocdn.net/dn/bSKi7r/btr5rfdasSJ/xcF6vCun1mxLYEoPKCU33K/img.png)
[그림 10]을 보면 index 4가 데이터프레임 두번째 행에 있습니다. 대신 다섯 번째 행부터 아래 행이 모두 삭제되었습니다. 이것으로 .iloc[:n]에서 지정하는 인덱스는 표기된 인덱스가 아니라 실질적(?) 인덱스를 가리킨다는 것을 확인했습니다.
4) 여러 조건에 해당하는 행 삭제
#여러 조건에 해당하는 행 선택 삭제
df_07 = df_02.drop(df_02[(df_02['name']=='홍길동') & (df_02['ID']=='apple')].index)[코드 11] 여러 조건에 해당하는 행 선택 삭제
1) 원본 데이터프레임.drop()
2) 원본 데이터프레임[].index
3) (원본 데이터프레임[조건식이 작동할 열 이름]=='홍길동') & (원본 데이터프레임[조건식이 작동할 열 이름]=='apple')[코드 12] 코드 뜯어보기
여러 조건을 입력하고, 조건에 해당하는 행만 선택적으로 제거하는 방법이 있습니다. [코드 11]은 그 예시입니다. 기본적으로 .drop() 메서드를 사용합니다. 그 안의 괄호가 굉장히 복잡하게 연결되어 있습니다. 괄호의 바깥부터 차례대로 정리한 것이 [코드 12] 입니다.
1) 원본 데이터프레임.drop()은 메서드 선언의 가장 바깥 부분입니다.
그 안에는 삭제하고자 하는 index를 입력하기 위해서 2) 원본 데이터프레임[].index 를 입력합니다. 대괄호[] 안에 조건식을 넣게 됩니다.
3)이 바로 그 조건식입니다. 조건이 하나일 때는 소괄호() 없이 코드를 넣어도 됩니다. 하지만 복수의 조건을 연결할 때는 소괄호로 한 번, 식을 묶어서 논리연산자로 더해줍니다. 각 괄호 안에 조건식을 보면 원본 데이터프레임[조건식 적용 열] + 논리연산자 + 데이터 값으로 구성되어 있습니다.
[코드 11]은 df_02 데이터프레임에서 'name' 열의 '홍길동'과 같은 데이터 값을 가진 행과 df_02 데이터프레임에서 'ID'열의 'apple' 데이터 값을 가진 행을 삭제합니다.

![[그림 11] 조건식으로 행 삭제](https://blog.kakaocdn.net/dn/pwmCO/btr5quPr8d0/Cgk5Wk6uWOGD0kZhnWxj0K/img.png)
[그림 11]처럼 df_02 데이터프레임의 'name' 열에서 '홍길동'을 데이터 값으로 갖는 행은 index 0, 8 행이었습니다. 조건식을 실행한 df_07 데이터프레임에서는 'ID'열의 데이터 값이 'apple'과 일치하는 index 0 행만 삭제된 것을 확인 할 수 있습니다. 조건식에서 논리 연산자로 두 조건식을 &(AND) 논리 연산자로 엮었기 때문입니다.
갈무리
이상으로 pandas Dataframe에서 행과 열을 삭제하는 방법에 대해서 각각 알아보았습니다. 기존적으로 drop() 메서드가 사용되고 일부 .iloc[] 가 사용되었습니다. 일반적인 상황에서는 drop() 메서드를 자주 사용하게 될 것입니다. 본인의 코드에 맞는 적절한 방법을 찾아 적용하시기 바랍니다.
'개발고생일지 > 파이썬' 카테고리의 다른 글
| pandas Dataframe 데이터프레임 정보 조회 방법들 (0) | 2023.03.27 |
|---|---|
| pandas Dataframe 데이터 값 정렬 .sort_index(), .sort_values() (0) | 2023.03.27 |
| pandas Dataframe(데이터프레임) 행, 열 합치기 (병합) (0) | 2023.03.26 |
| pandas dataframe(데이터프레임) index(행) 추가 (0) | 2023.03.25 |
| pandas dataframe(데이터프레임) columns(열) 추가 (0) | 2023.03.25 |